擴(kuò)散模型再下一城! 故事配圖這個活可以交給AI了
生成具有故事性的漫畫可不是那么簡單,不光要保證圖像質(zhì)量,畫面的連貫性也占有非常重要的地位,如果生成的....
用于NAT的選擇性知識蒸餾框架
盡管NAT在擁有許多潛在的優(yōu)勢,目前的工作中這類模型仍然在很大程度上依賴于句子級別的知識蒸餾(seq....
介紹四個為語言生成設(shè)計的預(yù)訓(xùn)練模型
BERT: 只有Transformer Encoder部分,隨機(jī)MASK掉一些token,然后利用上....
為什么不同模態(tài)的embedding在表征空間中形成不同的簇
文中將一些經(jīng)典的多模態(tài)對比學(xué)習(xí)模型中兩個模態(tài)的embedding,通過降維等方法映射到二維坐標(biāo)系中。
一種將信息直接編碼到預(yù)訓(xùn)練的語言模型中的結(jié)構(gòu)
邊界信息的挖掘,對于NER的任務(wù)是非常重要的,這種類似于分詞的功能,能夠很好的挖掘到詞語,并且把一個....
如何使用CLM自身的embedding來得到OOD score?
如果直接套用classification任務(wù)中使用MSP作為OOD score的話,那么對于NLG問....
基于VQVAE的長文本生成 利用離散code來建模文本篇章結(jié)構(gòu)的方法
寫在前面 近年來,多個大規(guī)模預(yù)訓(xùn)練語言模型 GPT、BART、T5 等被提出,這些預(yù)訓(xùn)練模型在自動文....
從統(tǒng)一視角看各類高效finetune方法實現(xiàn)最優(yōu)tuning框架設(shè)計
Adaptor核心是在原Bert中增加參數(shù)量更小的子網(wǎng)絡(luò),finetune時固定其他參數(shù)不變,只更新....
采用檢測框架CoP通過控制偏好檢測事實不一致
一致性評估的本質(zhì)是衡量摘要Y受原文X支持的程度,也就是衡量X到Y(jié)的因果效應(yīng)。直接使用常規(guī)推理過程的生....
基于本體的金融知識圖譜自動化構(gòu)建技術(shù)
本評測任務(wù)參考 TAC KBP 中的 Cold Start 評測任務(wù)的方案,圍繞金融研報知識圖譜的自....
FRNet:上下文感知的特征強(qiáng)化模塊
現(xiàn)有的工作已經(jīng)注意到了這個問題,例如 IFM、DIFM 等,但是他們僅僅在不同的實例中為相同特征賦予....
谷歌提出Flan-T5,一個模型解決所有NLP任務(wù)
這里的Flan指的是(Instruction finetuning),即"基于指令的微調(diào)";T5是2....
介紹兩種高效的參數(shù)更新方式LoRA與BitFit
NLP一個重要的范式包括在通用領(lǐng)域數(shù)據(jù)上的大規(guī)模預(yù)訓(xùn)練和在特定任務(wù)或者領(lǐng)域上的微調(diào)。
圖模型在方面級情感分析任務(wù)中的應(yīng)用
方面級情感分析(Aspect-based Sentiment Analysis, ABSA)是一項細(xì)....
一篇文章講清楚交叉熵和KL散度
什么情況下產(chǎn)生的平均驚喜最高呢?自然是不確定越高平均驚喜越高。對于給定均值和方差的連續(xù)分布,正態(tài)分布....
面向Aspect情感分析的自動生成離散意見樹結(jié)構(gòu)
在本文中,我們探索了一種簡單的方法,為每個方面自動生成離散意見樹結(jié)構(gòu)。用到了RL。
從預(yù)訓(xùn)練語言模型看MLM預(yù)測任務(wù)
為了解決這一問題,本文主要從預(yù)訓(xùn)練語言模型看MLM預(yù)測任務(wù)、引入prompt_template的ML....
用于中文縮略詞預(yù)測的序列生成模型研究
縮略詞是單詞或短語的縮寫形式。為了方便寫作和表達(dá),在文本中提及某個實體時,人們傾向于使用縮寫名稱而不....
基于性別的暴力(GBV)的語言表達(dá)如何影響責(zé)任認(rèn)知
不同的語言表達(dá)可以通過強(qiáng)調(diào)某些部分從不同的角度來概念化同一事件。該論文調(diào)查了一個具有社會后果的案例:....
求一種基于結(jié)構(gòu)統(tǒng)一M叉編碼樹的求解器解決方案
數(shù)學(xué)問題 (英文叫Math Word Problem,簡稱MWP) 的求解要求給定一段描述文本,其中....
一種新型的雙流注意力增強(qiáng)型BERT來提高捕捉句子對中細(xì)微差異的能力
因此,該論文提出一種新型的雙流注意力增強(qiáng)型bert(DABERT,Dual Attention En....
幫助弱者讓你變得更強(qiáng):利用多任務(wù)學(xué)習(xí)提升非自回歸翻譯質(zhì)量
沿著這個思路,我們希望能夠為NAR模型提供更具信息量的學(xué)習(xí)信號,以便更好地捕獲目標(biāo)端依賴。同時,最好....
列舉一些常見的數(shù)據(jù)問題以及解決方案
其次,有些數(shù)據(jù)集,和很多原因有關(guān),無論是訓(xùn)練集還是測試集,準(zhǔn)確率可能都只是在六七十甚至更低,我們其實....
簡單總結(jié)幾種NLP常用的對抗訓(xùn)練方法
對抗訓(xùn)練本質(zhì)是為了提高模型的魯棒性,一般情況下在傳統(tǒng)訓(xùn)練的基礎(chǔ)上,添加了對抗訓(xùn)練是可以進(jìn)一步提升效果....
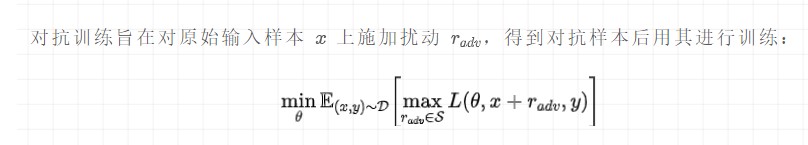
介紹大模型高效訓(xùn)練所需要的主要技術(shù)
隨著BERT、GPT等預(yù)訓(xùn)練模型取得成功,預(yù)訓(xùn)-微調(diào)范式已經(jīng)被運用在自然語言處理、計算機(jī)視覺、多模態(tài)....
建立計算模型來預(yù)測一個給定博文的抱怨強(qiáng)度
在計算語言學(xué)中,先前的研究主要集中在建立自動分類模型來識別抱怨是否存在。Jin提供了一個數(shù)據(jù)集,基于....
CogBERT:腦認(rèn)知指導(dǎo)的預(yù)訓(xùn)練語言模型
另一方面,從語言處理的角度來看,認(rèn)知神經(jīng)科學(xué)研究人類大腦中語言處理的生物和認(rèn)知過程。研究人員專門設(shè)計....
基于使用對比學(xué)習(xí)和條件變分自編碼器的新穎框架ADS-Cap
在本文中,我們研究了圖像描述(Image Captioning)領(lǐng)域一個新興的問題——圖像風(fēng)格化描述....
對話系統(tǒng)中的中文自然語言理解(NLU)(3.1)學(xué)術(shù)界中的方法(聯(lián)合訓(xùn)練)
槽位填充任務(wù)(Slot Filling Task) 當(dāng)模型聽懂人類的意圖之后,為了執(zhí)行任務(wù),模型便需....
摘要模型理解或捕獲輸入文本的要點
Abstract Intro ? 盡管基于預(yù)訓(xùn)練的語言模型的摘要取得了成功,但一個尚未解決的問題是生....





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)